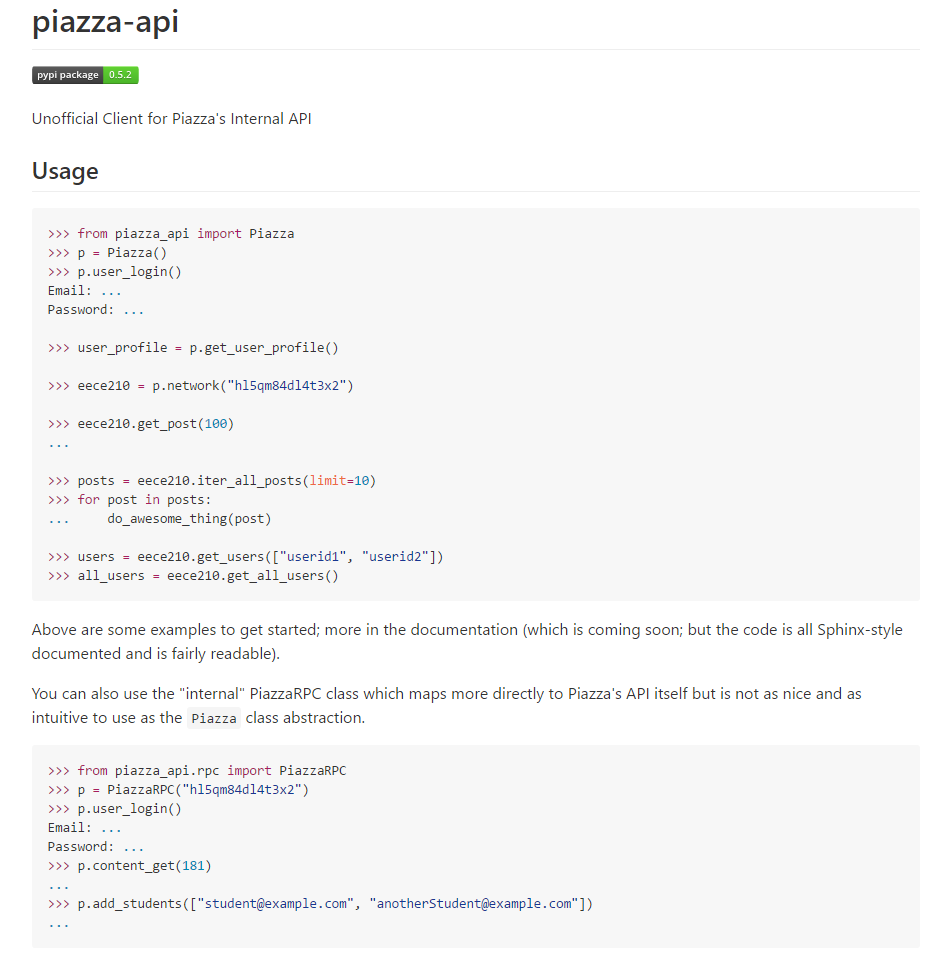
POSTS
Reverse Engineering Piazza's API
- 8 minutes read - 1525 words
Motivation
The private API is a myth. Piazza has an internal, i.e., private, API. This gist is a proof of that concept. It is, of course, every self-respecting snooping user’s responsibility to publicize these.piazza-api (Click for GitHub)
I wrotepiazza-api a while ago when it was just essentially a more formal version of alexjlockwood’s gist. About a week ago I got an email from an Associate Professor from UMD asking about piazza-api (specifically, authenticating with “Share Your Class” demo users, and additionally if I had any further knowledge of Piazza’s API). Authenticating with demo users was easy enough (grab the cookie from the response when visiting using the anonymized URL and you’re good to go). Of course, I had no further knowledge of Piazza’s API, because it was “private”. His inquiry intrigued me, however, and I decided to investigate (because curiosity and the aforementioned responsibility).
Capturing API Calls
There are several ways that I could go about doing this. I could inspect the client code for API calls. I could use Chrome Dev Tools. Or I could use Fiddler (not because it’s any better than CDT, it’s just another option). I will be using a bit of both here. If you want to skip the Fiddler setup, simply press F12 and open the Network tab if you’re using Chrome.Meet Fiddler
 Fiddler In a Nutshell
Fiddler In a Nutshell
Fiddler is a proxy that captures all HTTP(S) requests and responses going in and out of your system. It’s a great tool for web debugging (and in this case, reverse-engineering private APIs). There are several alternatives, such as Charles, however, Fiddler is free (and manages to be excellent at the same time). Anyways, enough praise; the point I’m trying to make is that a tool like Fiddler makes this dead easy.
We need to do just a bit of configuration first.
Decrypting HTTPS Traffic
Piazza uses HTTPS (as it rightfully should). To be a useful middleman, Fiddler needs to install a Root CA so that traffic going out and coming in can be decrypted and read. This can be painlessly configured in Fiddler Options. This is a great trust exercise between you and Fiddler. Note that if you are using Chrome Dev Tools instead, this is not necessary.Filter Through Relevant Captures
By default, Fiddler will log all sessions from everything and everywhere. Since we don’t particularly care about, well, any traffic other than Piazza, let’s filter only it through.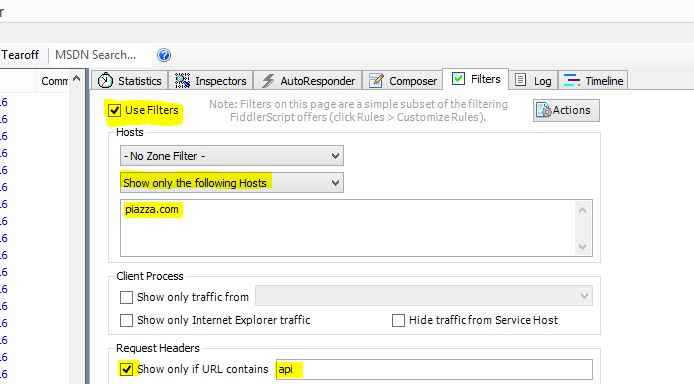 Filtering through only traffic to piazza.com with ‘api’ in the URL seems reasonable
Filtering through only traffic to piazza.com with ‘api’ in the URL seems reasonable
Generating Captures
At this point, we can head on over to Piazza and just start clicking around to see what API calls are made. Fiddler will capture requests and show us only the filtered ones that we desire.The following is a capture from several clicks around the interface.
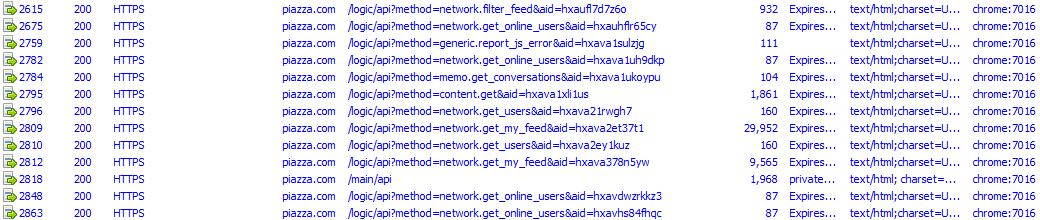
Let’s break these down and map by action:
 Logging in from home page, and forwarded to my last viewed class page
Logging in from home page, and forwarded to my last viewed class page
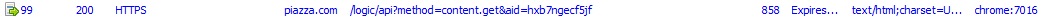 Clicking on a post
Clicking on a post
 Clicking on “Updated”, i.e., filtering feed to show only what is unread by the user
Clicking on “Updated”, i.e., filtering feed to show only what is unread by the user
 Clicking on “Following”, i.e., filtering through only posts that I am following
Clicking on “Following”, i.e., filtering through only posts that I am following
 Clicking on a folder
Clicking on a folder
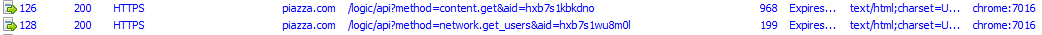 Clicking on a post again; 128 is getting users that participated on the post, it seems
Clicking on a post again; 128 is getting users that participated on the post, it seems
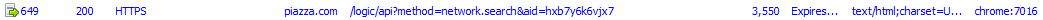 Used search to do a search for “practice final”
Used search to do a search for “practice final”
 Click on “Class Statistics” on top right
Click on “Class Statistics” on top right
Analysis
From looking at the above requests and responses, and making a few test requests, I made the following observations:- Everything is a POST (well, almost, everything).
- All requests have a method query param, however, the request body has this as well and it’s the one that seems to matter. That is, one can leave out the method query param in a request and it still works fine so long as the method is in the body.
- aid is another such query param, but it seems to be unnecessary. aid might potentially be a sort of “referrer” identifier? It seems to be unique for each request, but it’s ultimately unimportant because the API still works fine without it.
- All endpoints are under
/logic/api, except for Class Statistics which are under/main/api; odd choice, but then again, the API design is rather odd overall (as goes for most real-world APIs) - Request bodies…
- are expected to have a method key
- are expected to contain a params key
- … in this way, they seem to almost mirror actual function calls
- … even, remote procedure calls…
Looking at the wikipedia page for JSON-RPC, everything we’ve seen so far maps well to JSON-RPC. Although, it only seems to be JSON-RPC-ish, much like most so-called REST APIs that only take a few common elements from REST’s design.
Closer Request Inspection
/logic/api Methods
method: network.get_users
params:
ids ([string,… ]): List of user IDs
nid (string): ID of class
This method seems simple enough; give it a list a students IDs and it returns information on those students; mostly harmless stuff in here.
method: network.get_my_feed
params:
limit (number): Number of posts from feed to get
nid (string): ID of class
offset (number): The offset from which to start retrieving feed posts
sort (string): Most probably how to sort the feed retrieved; only seen as “updated” so far
This method seems to retrieve the “feed” you see as student when logged in to the home page; contains different data from content.get.
method: content.get
params:
cid (string): ID of the post to retrieve
nid (string): ID of the class
This is the one that gets the whole post (as it is needed only when one actually clicks on the whole post to see it).
method: network.filter_feed
params:
nid (string): ID of the class
sort (string): Most probably how to sort the feed retrieved; only seen as “updated” so far
updated (number): Most likely a boolean flag, i.e., set to 1 to filter feed with only posts to see that have updated since last viewed by you
following (number): Same as “updated” above; set this to 1 to filter through only posts that you are following
folder (number): Same as the above flags; set to 1 to filter feed so that it shows posts from only a single folder
filter_folder (string): Name of the folder you wish to show posts from
This method seems to return the same results as network.get_my_feed except for, you guessed it, you can specify the additional filters of updated or following that map to clicking Updated or Following on the web UI. Additionally, you can provide the folder filter as well.
method: network.search
params:
nid (string): ID of the class
query (string): The search query
This method is similar to network.filter_feed in the content of its results, except in this case, the filter is the search query.
method: user_profile.get_profileGets the current user’s profile; no params seen.
/main/api Methods
method: network.get_stats
params:
nid (string): ID of the class
anonymize: Was set to “False” when performing request from UI; mostly likely can be set to “True” to anonymize some results from the request
Triggered by clicking “Statistics” in the top bar; returns the statistics you’d expect to generate the page, including the graph on the page as well.
… And More?
There are most likely many more methods available in the API, such as for post creation and different methods for instructors; however, for the sake of brevity of this post, I am not going to investigate and document everything and simply go with what I have learned thus far and translate that into a usable Python client for the API.Making a (Somewhat Sane) Piazza Client
Now comes the time to translate this into a somewhat usable client. Piazza’s API itself is okay, but doesn’t come across as one with the most usable design and perhaps one we don’t want to mirror in the design of the client.Our client’s API ideally needs to have a better abstraction on top of Piazza’s JSON-RPC API than the RPC API itself. However, our client still needs to have a mapping close to the RPC API itself so that we can easily patch it for any future changes to Piazza’s API.
The solution to this is simple; as a base layer, we create a direct-ish mapping to the RPC API. And on top of that, we build additional abstractions with a more usable and pleasant design.
For that purpose, the top-level abstraction I have created is the Piazza class. With this, you can log in, view your user profile, and do one more thing, which is create a Network instance. Network contains the rest of the methods and are methods that concern particular networks, i.e., classes.
A design like this, if done correctly (which I hopefully have done an okay job of here), neatly decouples any warts of Piazza’s RPC API and allows the client’s user API to stay untouched in case of any breaking changes to Piazza’s API. The patches to these changes can be made in the “direct-ish mapping to the RPC API” in the client.
The result is a client, to which there can definitely be much more work devoted, but, is a reasonably usable one: